
零基础写Python爬虫,爬图片(scrapy入门)

前言:
都说python写爬虫凶得很,昨天就花了一天时间写了一个小爬虫,感觉还不错,总共100行代码不到就可以得到数据。还是分享下哈经验,如果是大佬可以按ctrl + w了。
之前在Android 上写过一个爬虫,封装了一下,可以爬取学校教务信息的几乎所有信息。
学生只需要登录,啥子成绩、消费记录、课表都出来了(想表达的就是爬虫大到可做大数据,小的也能简便我们的生活)
好了,废话不多说了,进入正题吧!
目的:
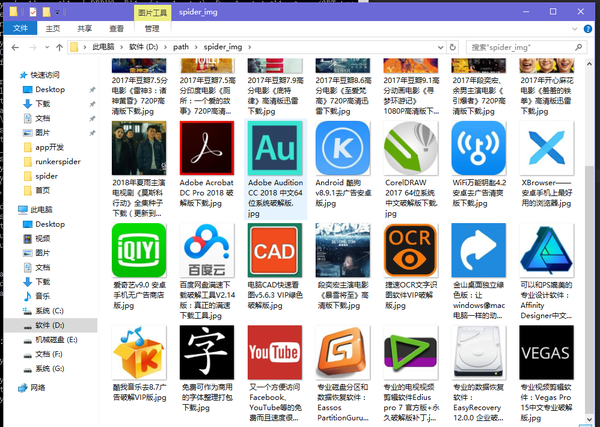
1:爬取某资源分享网的文章信息
2:保存文章对应的缩略图
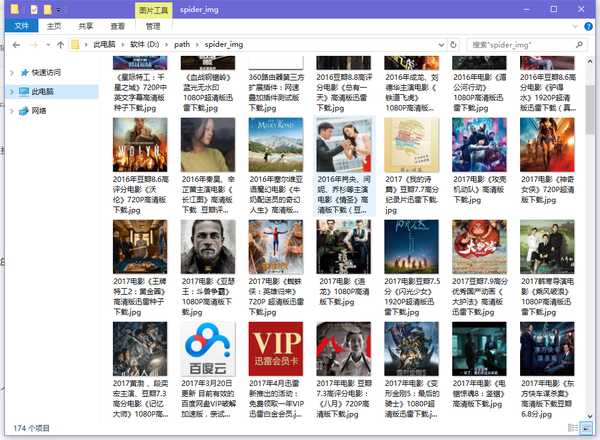
想挂两张效果图,免得你门去拉滚动条
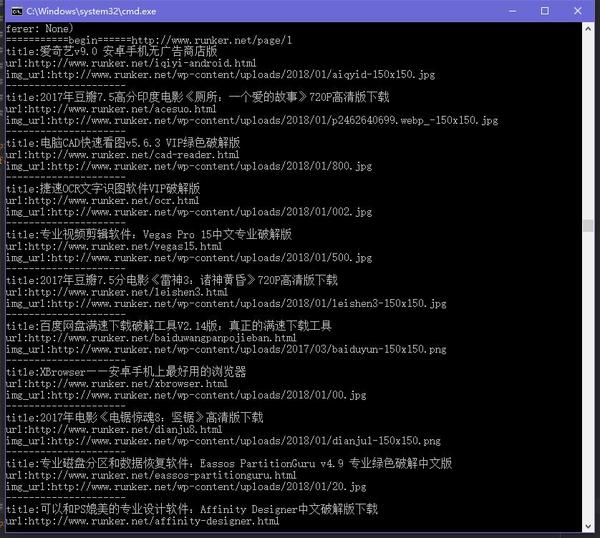

对应的图片:

安装Python
好了,我们还是先把 2条蟒蛇 安装起。这里的步骤写的很详细,我就不再重复了,我安装的环境是:Python2.7
安装教程: 安装Python
安装常用的模块
也是照着步骤,下一步下一步就OK
教程: 安装常用模块
安装pywin32
在windows下,必须安装pywin32,安装地址: http://sourceforge.net/projects/pywin32/
下载对应版本的pywin32,直接双击安装即可,安装完毕之后验证:

在python命令行下输入import win32com
如果没有提示错误,则证明安装成功
安装Pip
在安装python的时候勾上就可以了
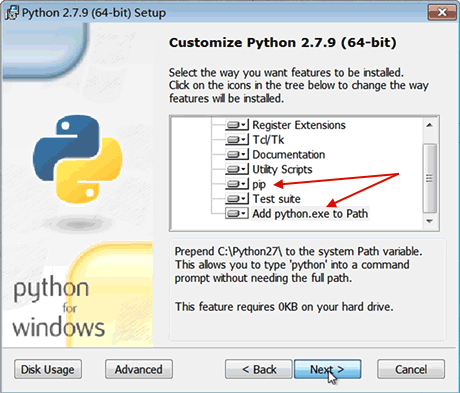

特别要注意选上pip和Add python.exe to Path,然后一路点“Next”即可完成安装。
安装Scrapy
最后就是激动人心的时刻啦,上面的铺垫做好了,我们终于可以享受到胜利的果实啦!
执行:pip install Scrapy(不是在python命令下执行哦)
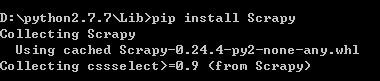
pip 会另外下载其他依赖的包,这些就不要我们手动安装啦,等待一会,大功告成!
验证安装,输入 Scrapy
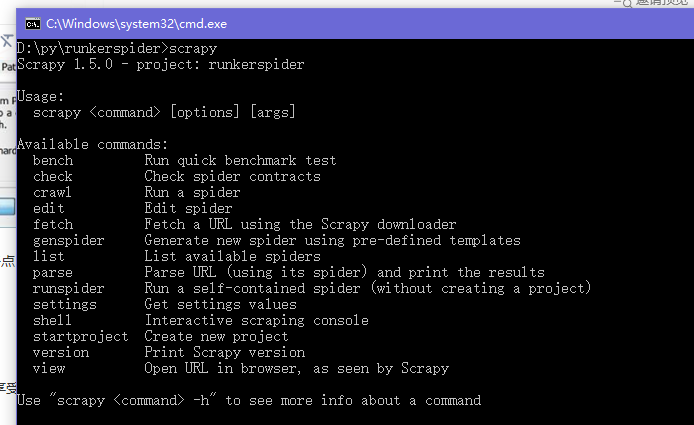

好了,安装完成Scrapy爬虫框架,我们就可以开心的写代码了
我们还是先附上Scrapy的官方文档
官方文档: Scrapy 1.5 documents
英语不好的同学点这里: Scrapy入门教程中文版
创建项目
在开始爬取之前,您必须创建一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:
scrapy startproject runkerspider
该命令将会创建包含下列内容的 runkerspider 目录:
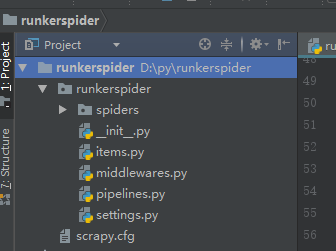
这些文件分别是:
scrapy.cfg: 项目的配置文件- runkerspider
/: 该项目的python模块。之后您将在此加入代码。 - runkerspider
/items.py: 项目中的item文件. - runkerspider
/pipelines.py: 项目中的pipelines文件. - runkerspider
/settings.py: 项目的设置文件. - runkerspider
/spiders/: 放置spider代码的目录.
编写爬虫程序
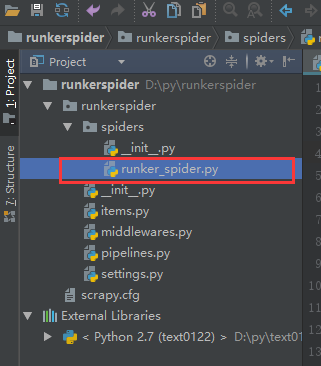
在spiders文件夹下创建.py文件
代码中注释已经很详细了,就不解释了,关于解析html内容,使用的是自带的xpath,之前使用java的jsou。
对应网站:(已屏蔽)
爬虫目标:
- 文章Title
- 文章的url
- 图片的缩略图


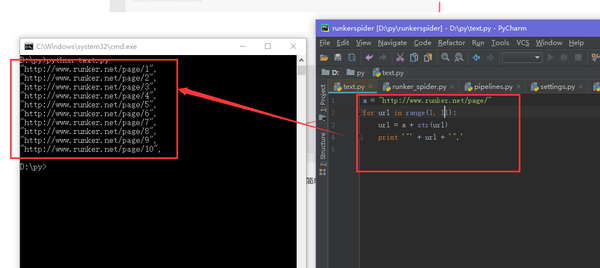
我们先找到需要爬取的网页


很容易就发现规律了,那么我们先爬取前10页的数据吧,简单写个循环

在spider目录下创建爬虫文件
我们打开对应的网站,用火狐浏览器自带的开发者工具找到需要的内容在 <div id="content">标签下。但是发现标签里的第一个和最后一个并不是我们想要的内容,所以直接过滤掉。
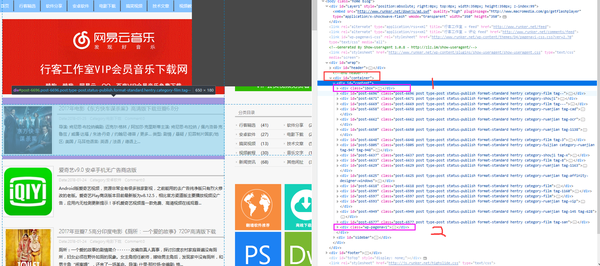


我们分析层级结构,通过自带的xpath 找到对应的内容
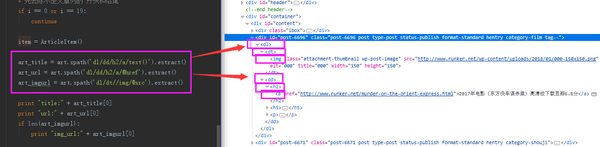

好,我们能找到对应的内容了,但是需要将内容存储下来,平且还要下载图片,按说明文档,我们编写items.py
按照官方的文档写就可以了,注意下面2个属性,是为了下载图片定义的(文档写的)
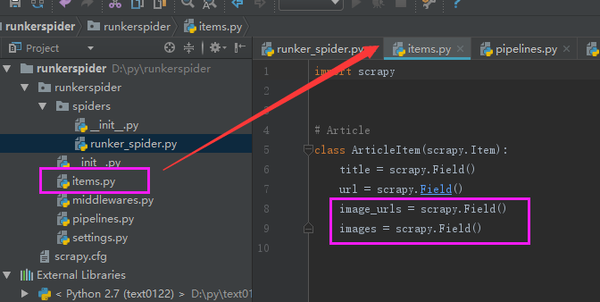

然后再到爬虫文件赋值(注意,赋值要下载图片地址的时候要将整个数组进行复制哦)
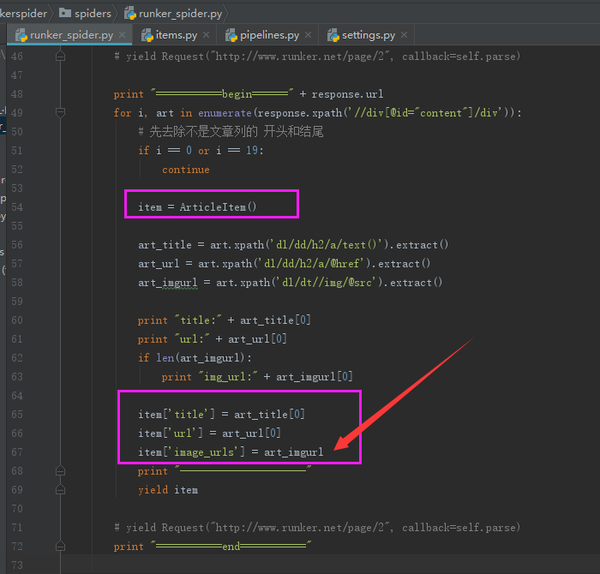
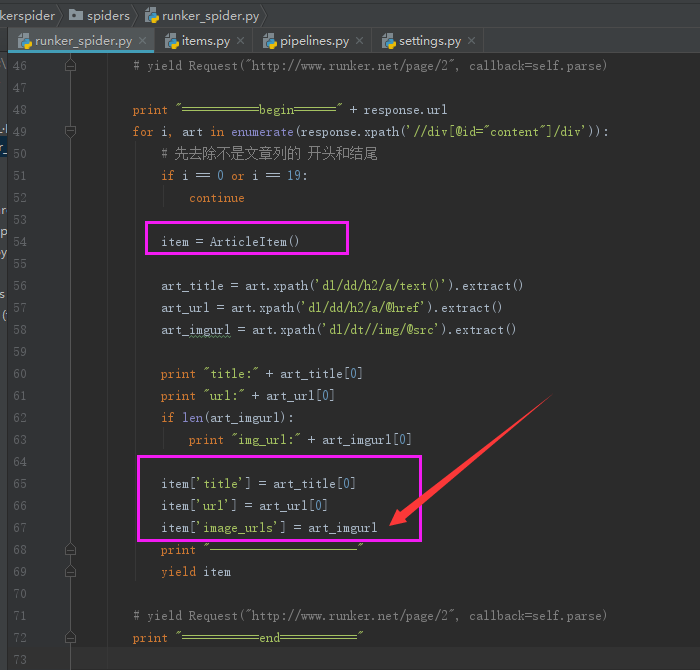
好了,可以运行了,我们先进入到项目的根目录

进入之后直接敲 scrapy crawl runker(刚才我们在runker_spider.py 里定义的name)
哇!哇!哇!哇!,就看见程序再开始跑了,数据一串串的出来
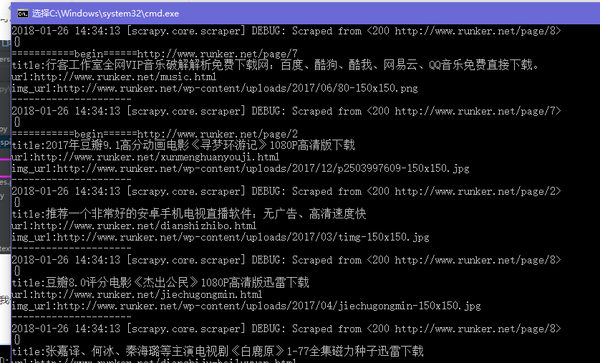

用框架就是好,直接是多线程再运行,一会儿就跑完了,一共180条文章数据。
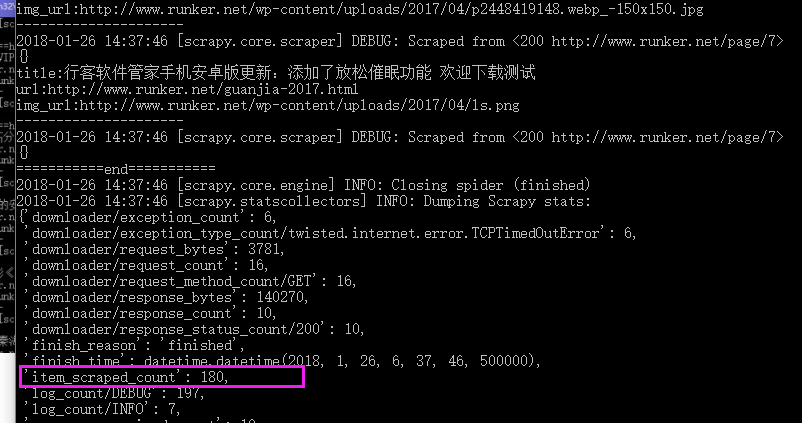

还是先把 runker_spider.py 问价的代码贴一下。
# -*- coding: utf-8 -*-
import scrapy
from runkerspider.items import ArticleItem
class RunkerSpider(scrapy.spiders.Spider):
# 定义爬虫名 之后在执行scrapy crawl runker
name = "runker"
# 允许访问的域名范围,规定爬虫只爬取这个域名下的网页
allowed_domain = ["runker.net"]
# 要爬取的网站
start_urls = [
"http://www.runker.net/page/1",
# 自行补齐
"http://www.runker.net/page/10"
]
def parse(self, response):
print "===========begin======" + response.url
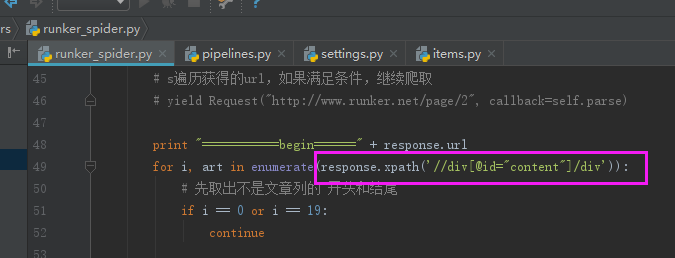
for i, art in enumerate(response.xpath('//div[@id="content"]/div')):
# 先去除不是文章列的 开头和结尾
if i == 0 or i == 19:
continue
item = ArticleItem()
art_title = art.xpath('dl/dd/h2/a/text()').extract()
art_url = art.xpath('dl/dd/h2/a/@href').extract()
art_imgurl = art.xpath('dl/dt//img/@src').extract()
print "title:" + art_title[0]
print "url:" + art_url[0]
if len(art_imgurl):
print "img_url:" + art_imgurl[0]
item['title'] = art_title[0]
item['url'] = art_url[0]
item['image_urls'] = art_imgurl
print "---------------------"
yield item
print "===========end==========="
items.py 代码:
import scrapy
# Article
class ArticleItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()跑数据没有问题了,之后就是解决图片的保存了,管道文件 pipelines.py
在这之前我们的先配置一下配置文件
1:设置保存图片的路径 IMAGES_STORE = '/path/spider_img'
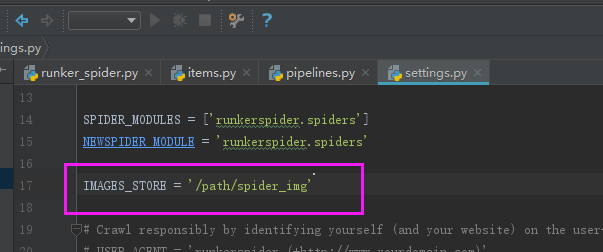

2:打开图片下载配置
ITEM_PIPELINES = { 'runkerspider.pipelines.ArtImagesPipeline': 1}
注意写的配置要对应了,写成自己的项目文件
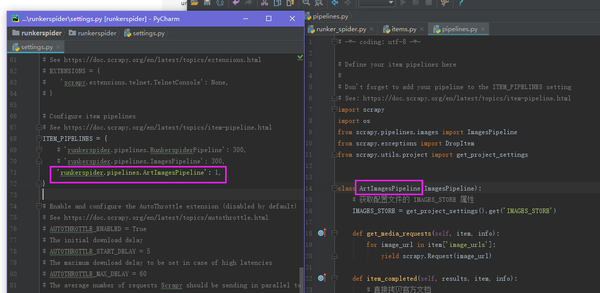

好了,剩下就是编写 pipelines.py
先添加这几个引用:
import scrapy
import os
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.utils.project import get_project_settings# 获取配置文件的 IMAGES_STORE 属性 (就是我们刚才在setttings.py定义的)
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
最后在后面写2句代码,我们以文章的标题进行命名,不然默认的好像是以SHA1 命名的
os.rename((self.IMAGES_STORE + "/" + image_paths[0]), self.IMAGES_STORE + "/" + item['title'] + ".jpg")
item['image_paths'] = self.IMAGES_STORE + "/" + item['title'] + ".jpg" OK,还是贴一下 pipelines.py 代码吧
# -*- coding: utf-8 -*-
import scrapy
import os
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.utils.project import get_project_settings
class ArtImagesPipeline(ImagesPipeline):
# 获取配置文件的 IMAGES_STORE 属性
IMAGES_STORE = get_project_settings().get('IMAGES_STORE')
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
# 直接拷贝官方文档
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
os.rename((self.IMAGES_STORE + "/" + image_paths[0]), self.IMAGES_STORE + "/" + item['title'] + ".jpg")
return item好,我们这次还得把数据保存下来,不然就得去控制台复制了
哇,我们看到官方文档,可以将数据直接导出,而且还可以是多种格式
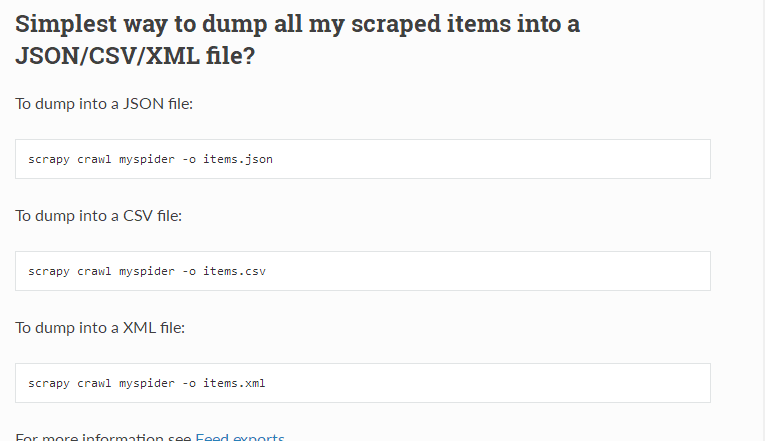

直接回车

我的天,心里默数了一下,13秒就完成了。

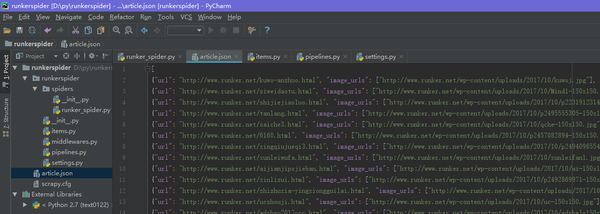
再到我们项目的根目录下发现 多出一个article.json,打开后发现,哇! 乱码了吗?

其实没有,不信我们把数据复制进一个解析器看看(直接百度json在线解析)
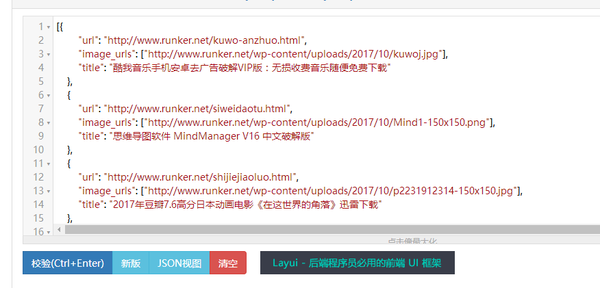

看吧,我们需要的东西出来啦~~哈哈
好了就写到这里了,我这个渣渣又要去到处水了~
加个SEO外链,请无视( 6471工作室)