数据分析-描述性分析

一.什么是统计学?与数据分析有什么关系?
统计是处理数据的一门科学,统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
统计学提供的是一套有关数据收集、处理、分析、解释并从数据中得出结论的方法;数据分析则是选择适当的统计方法研究数据,并从数据中提取有用信息进而得出结论。
二.描述性统计分析概论
1.概念
数据分析所用的方法可以分为描述统计方法和推断统计方法。
描述统计:研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法
推断统计:是研究如何利用样本数据来推断总体特征的统计方法。
比如:要了解一个地区的人工特征,不可能对每个人的特征一一测量,这种情况下就需要抽取部分个体样本进行测量,然后与根据所获得的样本数据对所研究的总体特征进行推断,这就是推断统计要解决的问题。
描述统计分析即对调查总体所有变量的有关数据进行统计性描述,简单来说就是将一系列复杂的数据集用几个有代表性的数据进行描述,进而能够直观的解释数据的变动,主要包括数据的离散程度分析、集中趋势分析、频数分析、分布以及一些基本的统计图形。
2.统计数据的类型
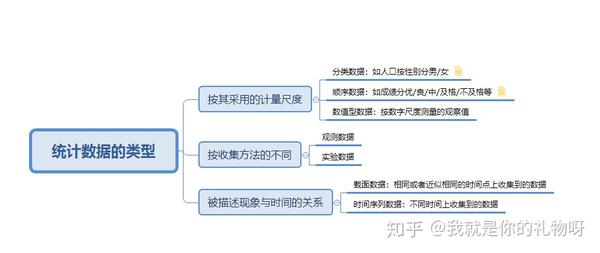

注意:分类数据和顺序数据说明的是事物的品质特征,通常用文字来表述的结果表现的都是类别,都可称为定性数据或者品质数据(qualitative data);
数值型数据说明的是现象的数量特征,通常是用数值来表现的,因此称为定量数据或数量数据(quantitative data)。
区分数据类型的意义:区分不同类型的数据采用不同的统计方法来处理和分析。如,分类数据我们通常计算各组的频数、众数、异众比率,进行列联表分析和卡方检验等;顺序数据可计算中位数和四分位差以及等级相关系数等;数值型数据可计算更多统计量、进行参数估计和假设检验等。具体在此文暂不展开,后续会结合实例再细述。
3.统计中常用的几个基本概念
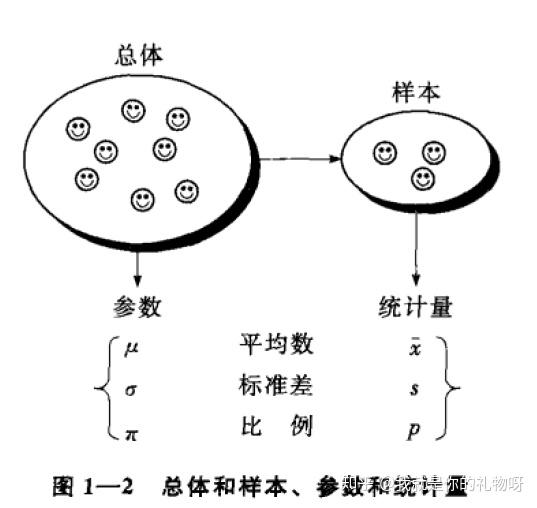
3.1总体与样本
总体:是包含所研究的全部个体(数据)的集合,通常由所研究的一些个体组成。
样本:是从总体中抽取的一部分元素的集合,构成样本的元素的数目称为样本量。抽样的目的是根据样本提供的信息推断总体的特征。
3.2参数和统计量
参数:是用来描述总体特征的概括性的数字度量,是研究者想要了解的总体某种特征值。
统计量:是用来描述样本特征的概括性数字度量,是根据样本数据计算出的一个量,因此统计量是样本的一个函数。
通常,是根据抽样计算样本统计量,再根据样本统计量去估计总体参数。比如,用样本平均数去估计总体平均数等
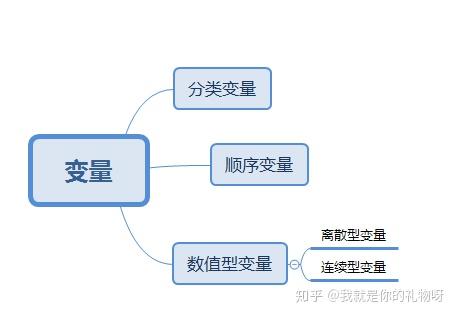
3.3变量
变量是说明现象某种特征的概念,特点是从一次观察到下一次观察结果会呈现出差别或变化。

三.描述性统计分析常用指标
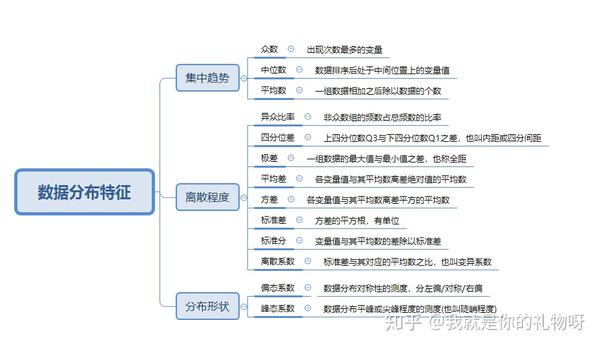
一般情况下描述数据分布的特征可以从以下3个方面进行测度和描述
一是分布的集中趋势,反应各数据向其中心值聚集的程度;二是分布的离散程度,反应数据远离中心值的趋势,三是分布的形状,反映数据分布的偏态和峰态
1.反应集中趋势的指标:众数、中位数和分位数、平均数
1.1 众数(mode):一组数据中出现次数最多的变量
特点:具有不唯一性,一组数据可能有多个众数,也有可能没有众数
应用:数据量多的较多时才有意义,主要适合分类数据的集中趋势测度值
1.2 中位数(median):一组数据排序后处于中间位置上的变量值
计算公式:中位数位置=(n+1)/2,式中,n为数据个数;
当n为奇数时,Me=在(n+1)/2位置上的数,
当n为偶数时,Me=[在(n/2)位置上的数+在(n/2)+1位置上的数]/2
特点:不受数据极端值的影响,
应用:数据分布偏斜程度大时适合使用,主要适合顺序数据的集中趋势测度值
1.3 四分位数(quartile):一组数据排序后处于25%和75%位置上的值,也就是用3个点将全部数据4部分,每部分包含25%的数据。中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为下四分位数Q1)和处在75%位置上的数值(称为上四分位数Q3)
计算公式:
四分位数位置的确定方法有多种,每种方法结果会有点差异,差异不大,如下介绍其中一种。
按照定义,四分位数位置确定方法步骤如下:
a.首先对一组数据排序,
b.Q1=n/4位置,Q2=2n/4=n/2位置, Q3位置=3n/4
c.如果位置是整数,四分位数就是该位置对应的值;
如果位置在0.5的位置,则取该位置两侧值的平均数;
如果位置在0.25或者0.75的位置,则取该位置下侧值加上按比例分摊位置两侧数值的差值;
举例解析:9个同学的语文成绩, 其中Nn代表第n个位置的数值
a.首先对9个数值排序
b.Q1位置=n/4=9/4=2.25,也就是第2和第3个位置之间0.25的位置上,即Q1=N2+(N3-N2)0.25=N2*0.75+N3*0.25
Q2位置=n/2=9/2=4.5,也就是第4和第5个位置之间0.5的位置上,即Q2=N4+(N5-N4)*0.5=N4*0.5+N5*0.5
Q3位置=3n/4=6.75,也就是第6和第7个位置之间0.25的位置上,即Q2=N6+(N7-N6)*0.75=N6*0.25+N7*0.75
应用:常应用在统计学中的箱线图绘制
箱线图(box plot):是由一组数据的最大值、最小值、中位数、两个四分位数这五个特征值绘制而成的,是一种用作显示一组数据分散情况资料的统计图。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。
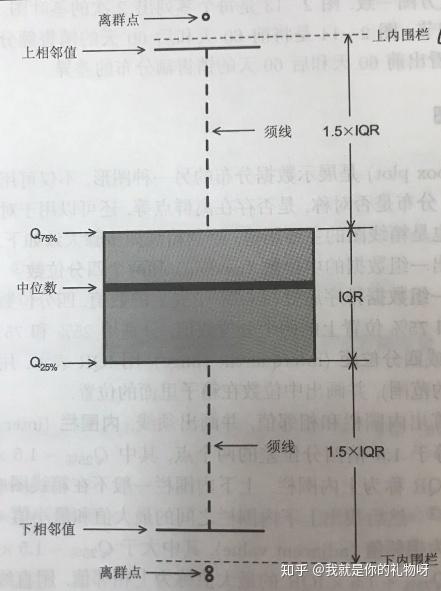



箱线图的特点:
a.箱子的大小取决于数据的四分位距,即IQR = Q3 - Q1(Q3和Q1分别为上下四分位数)。50%的数据集中于箱体,若箱体太大即数据分布离散,数据波动较大,箱体小表示数据集中。
b.箱体中的横线为中位数Q2(50%分位数),数据的最小估计值是Q1-1.5 IQR,最大估计是Q3+1.5 IQR
c.超过四分位差1.5倍距离的数值定义为离群点,即数据值 < Q1-1.5 * IQR(最小值)或数据值 > Q3+1.5 * IQR(最大值) ,均视为异常值(离群点)。
超过四分位差3倍距离的数值定义为极端值,即数据值 > Q3+3 * IQR 或 数据值 < Q1-3 * IQR ,均视为极值。
在实际应用中,不会显示异常值与极值的界限,而且一般统称为异常值。
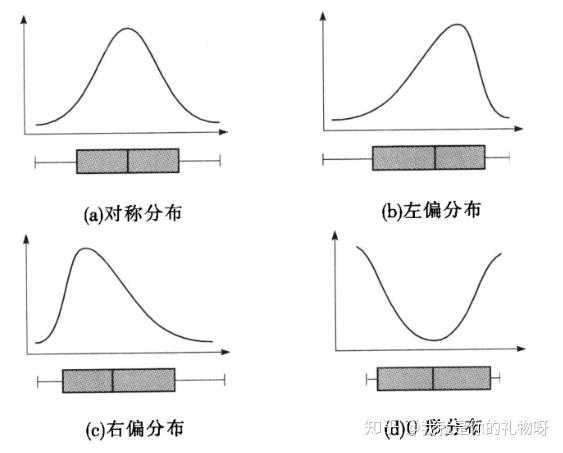
箱线图的应用:
1.反映一组数据的分布特征,如:分布是否对称,识别离群点(异常值)
2.对多组数据的分布特征进行比较
3.如果只有一个定量变量,很少用箱线图去看数据的分布,而是用直方图去观察。一般都要跟其余的定性变量做分组箱线图,可以起对比作用。

1.4 平均数(mean):一组数据相加之后除以数据的个数得到的结果
根据所掌握的数据不同,有多种不同的计算公式
a.简单平均数:
公式:=(N1+N2+...+Nn)/n,
应用:一般适用于未分组数据
b.加权平均数:
公式:=(M1f1+M2f2+...+Mnfn)/(f1+f2+...fn),Mn为各组的组中值,fn为出现的频数
应用:一般适用于适用于分组数据,且假定各组数据在组内是均匀分布
c.几何平均数:
公式=N1*N2...*Nn 乘积的n次方根
应用:一般掌握的变量值本身是比率时,用来计算平均比率 。主要用于计算现象的平均增长率
平均数的特点:极易受数据极端值的影响
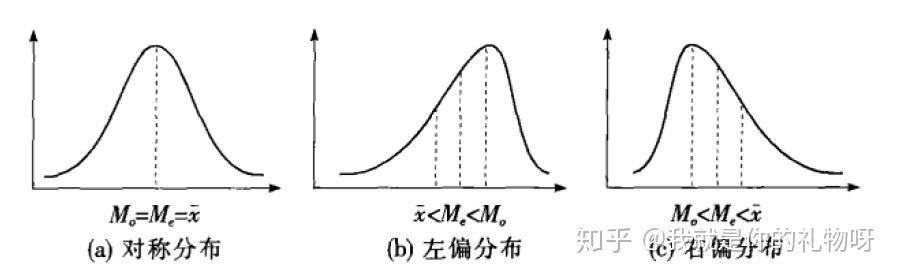
平均数的应用:针对数值型数据应用最广泛的集中趋势测度值,对于对称分布或者接近对称分布的数据,应选择平均数作为集中趋势的代表值,偏态分布的数据,使用中位数或者众数代表性更好。
众数、中位数与平均数之间的关系如下:
如果是左偏分布,说明数据存在极小值,必然拉动平均数向极小值一方靠,而众数和中位数由于是位置代表值,不受极值的影响。因此会有如下关系

2.反应离散程度的指标:
根据数据类型的不同,主要有异众比率、四分位差、方差、标准差、极差、平均差等
2.1 异众比率(variation ratio):非众数组的频数占总频数的比率
公式:Vr=(变量值的总频数Fn之和-众数组的总频数)/变量值的总频数Fn之和
应用:主要用于众数对一组数据的代表程度,数值越小,说明非众数组的频数占比越小,众数的代表性越好。
2.2 四分位差(quartile deviation):上四分位数Q3与下四分位数Q1之差,也叫内距或四分间距
公式:Qd=Q3-Q1
特点:不受极值的影响。数值越小,说明中间的数据越集中,数值越大,说明中间的数据越分散。
应用:反应中间50%数据的离散程度,不适合分类数据
2.3 方差和标准差
2.3.1.极差(range):一组数据的最大值与最小值之差,也称全距
公式:R=最大值-最小值
特点:计算简单,易于理解。但很容易受到极端值的影响
应用:只是简单的反应离散程度,因不能反映中间数据分散情况,所以不能准确描述数据分散程度。
2.3.2.平均差(mean deviation):各变量值与其平均数离差绝对值的平均数
公式:
未分组数据:

分组数据:
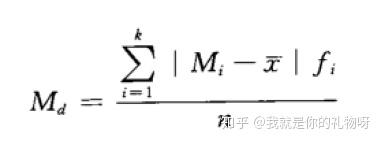
特点:计算麻烦,但是实际中应用较少,但是实际意义比较清楚,容易理解,能全面准确的反应一组数据的离散程度。
应用:平均差越大,说明数据的离散程度越大。
2.3.3 方差(variance):各变量值与其平均数离差平方的平均数
公式:


注意:样本方差是用样本数据个数减1后去除离差平方和,其中n-1称为自由度
标准差(standard deviation):即方差的平方根
特点:方差没有单位,标准差是有量纲的,与变量值计量单位相同,实际意义比方差更清楚。
应用:方差或标准差是实际中应用最广的离散程度测度值,能很好的反映数据的离散程度。实际问题分析更多的是用标准差。
2.4 标准分、离散系数和变异系数
2.4.1 标准分数(standard score):变量值与其平均数的差除以标准差后的值,也称为标准化值或z分数。
标准分数计算的是原始分数距离平均数有多少个标准差,也是常用的统计标准化公式,给出了一组数据中各数值的相对位置;
公式:

特点: 标准分数具有平均数为0、标准差为1的特性。实际上,z分数只是将原始数据进行线性变换,它并没有改变一个数据在改组数据中的位置,也没有改变数据的分布形状,只是将改组数据变为平均数为0、标准差为1
应用:
计算一组数据的各个数值的标准分数来测度每个数据在该组数据中的相对位置,可以判断一组数据是否有离群数据;
对多个具有不同量纲的变量进行处理时,常常需要对各变量进行标准化处理。
标准分数常用于经验法则和切比雪夫不等式
应用一:经验法则
又叫3-sigma法则或者68-95-99.7法则
当一组数据对称分布时,经验法则表明:
约有68%的数据在平均数1个标准差左右范围之内;
约有95%的数据在平均数2个标准差左右范围之内;
约有99%的数据在平均数3个标准差左右范围之内;
通常,3个标准差之外的数据在统计上称为离群点。
经验法则最常在统计中用于预测最后结果。在得到数据的标准差,并在可以收集确切的数据之前,该规则可作为一个对即将到来的数据的结果的粗略估计。该概率特别适用与一些需要消耗大量时间去收集的数据,或者甚至是不可能获得的数据。
应用二:切比雪夫不等式
当一组数据不是对称分布时,经验法则不再适用,此时适合切比雪夫不等式。
任意分布形态的数据,总是至少有(1-1/k的平方)的数据落在k个标准差范围之内,其中k为大于1的任意值,但不一定是整数。
对于k=2,k=3和k=4,不等式的含义是:
所有数据中,至少有3/4(或75%)的数据落在平均数2个标准差范围内。
所有数据中,至少有8/9(或89%)的数据落在平均数3个标准差范围内。
所有数据中,至少有15/16(或94%)的数据落在平均数4个标准差范围内 .
2.4.2 离散系数(coefficient of variation):也称变异系数,一组数据的标准差与其对应的平均数之比
公式:
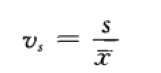
特点:离散系数是测度数据离散程度的相对统计量,主要是用于比较不同样本数据的离散程度。离散系数大,说明数据的离散程度也大;离散系数小,说明数据的离散程度大。
应用:对不同样本数据的离散程度进行比较时,适用于用离散系数(变异系数)。
为什么要计算离散系数?(非常重要)
a.方差和标准差是反映分散程度的绝对值,数值大小受原变量值本身或者 变量的平均数大小影响,原变量值本身大的,离散程度的测量值也就大
b.方差与标准差的计量单位与原变量值相同,不同计量单位的变量值离散程度测度值不同
为了消除变量值水平高低和计量单位不同对离散程度测度值的影响,所以需要计算离散系数。
3.反应分布形状的指标:偏态(Skewness)与峰态()
3.1 偏态
偏态是对数据分布对称性的测度,常用偏态系数SK(Coefficient of skewness)表示。
公式:三阶中心距/标准差的3次方




特点:
一般情形下,当分布对称时,Sk= 0;
分布不对称时,Sk> 0为右偏(或正偏)分布,且Sk值越大,右偏程度越高;
分布不对称时,Sk< 0为左偏(或负偏)分布,且Sk值越小,左偏程度越高;
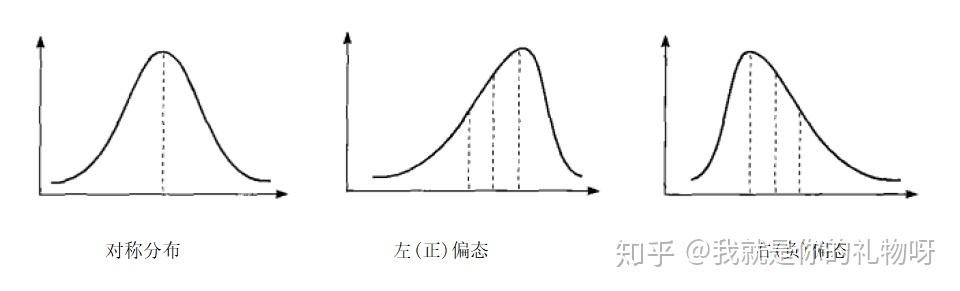

应用:在对称分布的情况下,一般是众数=中位数=平均值,但是在现实生活中,有些获取到数据并不是对称分布的,会产生数据偏态的情况;就会用偏度来描述数据分布的形状是否对称,偏斜的程度
3.2 峰态
偏态是对数据分布平峰或尖峰程度的测度(也叫陡峭程度),常用峰态系数K(Coefficient of kurtosis)表示,这个统计量需要与正态分布相比较。
公式:四阶中心距/二阶中心距的平方-3
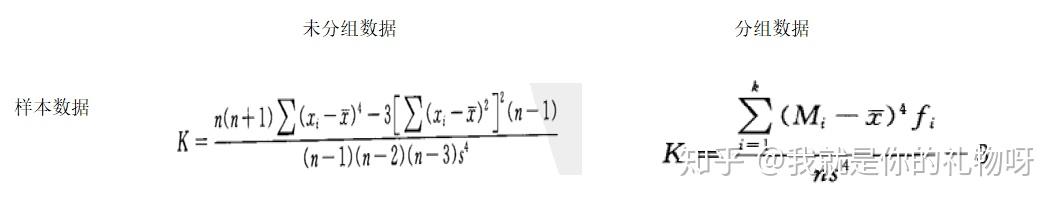

公式中将离差的4次方除以标准差s的四次方都是为了将峰态系数转化成相对数
特点:用峰态系数说明分布的尖峰和扁平程度,是通过与标准正态分布的峰态系数比较。
正态分布的峰态系数K=0,峰度为0表示该总体数据分布与正态分布的陡缓程度相同
K>0时表示该总体数据分布与正态分布相比较为陡峭,为尖峰分布,数据的分布更集中;
K<0时表示该总体数据分布与正态分布相比较为平坦,为扁平分布,数据的分布更分散。
注意:峰度系数公式也可以不减3,此时的比较标准是与3对比。当K>3是尖峰分布,K<3是扁平分布。


总结:

四.实战演练
1.熟悉数据集:
数据来源:阿里巴巴天池 https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
表1购买商品数据集中有7个字段,29971条记录,字段名对应的中文分别如下:
user_id:用户id
auction_id:物品编号(item_id)
cat_id: 商品种类ID(商品二级分类,表示商品属于哪个类别)
cat1: 商品种类ID(商品一级分类,表示商品属于哪个类别)
property:商品属性(属性值可以是大小,可以是尺码、毫升、品牌等)
buy_mount:购买数量
day:购买时间
表2婴儿信息表有3个字段,953条记录,字段名对应的中文分别如下:
user_id:用户id
birthday:出生日期
gender:性别(0女性;1男性;2未知的性别)
2.模拟用户行为,熟悉整个业务流程
假如我是个妈妈,正在为我的孩子选择童装,在淘宝网随机选择的店铺评分较高的一个店铺,我将关注以下信息:
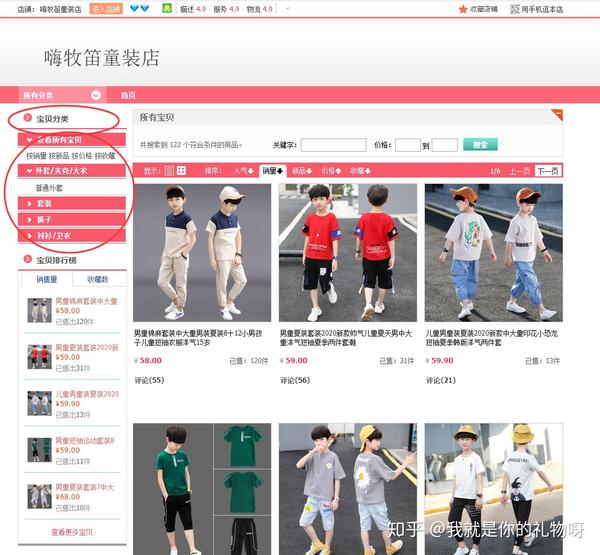

首先我会根据排序方式查看宝贝的分类,比如一级大类:外套/夹克/大衣,套装,裤子,衬衣/卫衣,接着点击我选择的一级大类为 套装,进入二级大类:夏季套装
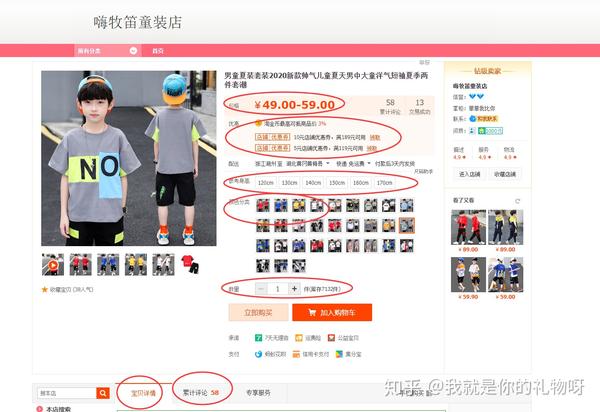



商品信息对应上述表一中的字段如下:
user_id:我的淘宝账号
auction_id:物品编号,比如打开详情页(图3)后台显示的货号B9195 19-225
cat_id: 商品二级分类,比如以上夏季套装
cat1: 商品一级分类,比如 宝贝分类中的套装
property:商品属性,如尺码、颜色、成分等
buy_mount:我购买的数量
day:我付款的日期
3.可以分析的业务问题可以有:
为了做好促销活动和供货准备,可分析以下问题
1)不同时间段日/月/季度的物品购买数量分别有多少
(可用字段 :购买时间,购买数量)
2)不同时间段日/月/季度的同一级大类商品购买数量分别有多少
(可用字段 :购买时间,购买数量,商品一级分类)
3)不同时间段日/月/季度的同二级小类商品购买数量分别有多少
(可用字段 :购买时间,购买数量,商品二级分类)
4)同一时间段月/季度 不同一级类别商品销量如何
(可用字段:购买时间,商品一级分类,购买数量)
5)同一时间段月/季度 同二级类别商品销量如何
(可用字段:购买时间,商品二级分类,购买数量)
6)不同一级类别购买数量分别有多少
(可用字段:商品一级类,购买数量)
7)同一类商品不同二级类别购买数量分别有多少,看哪种二级类别商品最受欢迎,其他类别是否做推广活动
(可用字段:商品一级类,商品二级分类,购买数量)
8)同一类商品同二级类别商品不同属性购买数量分别有多少,看哪种属性商品最受欢迎
(可用字段:商品一级分类,商品二级分类,商品属性,购买数量)
结合表2可分析以下问题
9)不同出生年龄段的儿童购买数量分别有多少
(可用字段:出生日期,购买数量)
10)不同性别的儿童购买数量分别有多少
(可用字段:性别,购买数量)
11)不同出生年龄段不同性别的儿童购买数量分别有多少
(可用字段:出生日期,性别,购买数量)
12)不同出生年龄段儿童对不同商品购买数量分别有多少
(可用字段:出生日期,商品一级种类,购买数量)
13)不同性别儿童对不同商品购买数量分别有多少
(可用字段:性别,商品一级种类,购买数量)
14)不同性别儿童对同商品种类不同属性商品购买数量分别有多少
(可用字段:性别,商品一级种类,商品二级种类,商品属性,购买数量)
15)不同年领段儿童对同商品种类不同属性商品购买数量分别有多少
(可用字段:出生日期,商品一级种类,商品二级种类,商品属性,购买数量)
4.你想从该数据集中得到哪些描述统计信息?
以上不同维度购买数量的平均值,同一商品不同年龄购买数 对应的中位数,不同年龄的购买数对应的四分位数,箱线图。
以上内容,思考的不是特别全面,需要看数据情况再分析异常情况或者提炼更有价值信息。只是趁这次写作机会,静心再次回顾下这些知识点。
本文参考资料:
1.贾俊平、何晓群、金勇.统计学(第四版):中国人民大学出版社,2009年
2.百度: 箱形图_百度百科
3. 箱线图boxplot - 喜欢吃面的Hush - 博客园
4. 偏度_百度百科