Titan/JanusGraph图数据库实战总结与深入分析

TitanDB/JanusGraph图数据库入门简介|实战总结|选型对比|存储结构深入分析
历史背景
JanusGraph图数据库,源自于TitanDB开源图数据库。TitanDB在2012年发布第一个版本,2015年被Datastax公司收购,后续不再维护导致项目停滞。
图数据库有2个最具代表性的查询语言:Cypher 及 Gremlin。Cypher是商业公司Neo4j出品,Neo4j图数据库在2007年发布了第一个版本,是商用图数据库领域的开拓者。Gremlin是Apache TinkerPop框架下规范的语言,TinkerPop属于当前图数据库领域最流行的框架规范,具备开源开放、功能丰富、生态完善等特点,拥有大量厂商支持(超过20家),Titan当属TinkerPop框架下最成功的开源图数据库实现,后续的不少图数据库或多或少借鉴了Titan的思想,Titan的几位核心作者包括:Dan、Matthias、Marko(okram)、Stephen(spmallette)等,其中的两位--Marko和Stephen同时也是TinkerPop的核心作者。个人在此致敬Titan和TinkerPop。
非常令人遗憾的是,Titan在2015年被收购后,其开源社区无人维护,否则以其前三年的势头来看,大有一统图江湖的趋势,不过没有如果。而Janus稍许弥补了这个遗憾,也算是后继之人,但是Janus绝大部分功能沿袭自Titan,没有更上一个台阶发扬光大,只是做了一些小修补。下面是对Titan/Janus的一些总结和分析。
2016年由其他人基于Titan源码Fork出了Janus,到目前(2020年)Janus已经合入了700多个Pull Request,主要包括:
- 支持Bigtable后端;
- 跟进TinkerPop框架的版本升级,目前已支持3.4.4;
- 后端存储升级与兼容,比如兼容Apache Cassandra 3.x, Apache HBase 2.x;
- 其它方面的增强与Bugfix,比如:新增Schema约束、新增HBase TTL、丰富GEO索引查询、优化AdjacentID查询等。
总结来说,在大方向上Janus对Titan改进并不多,主要包括2方面:
- 提供后端存储的版本升级与兼容适配;
- 新增极少的新Feature,大多是小修补,有少量功能增强。
整体架构
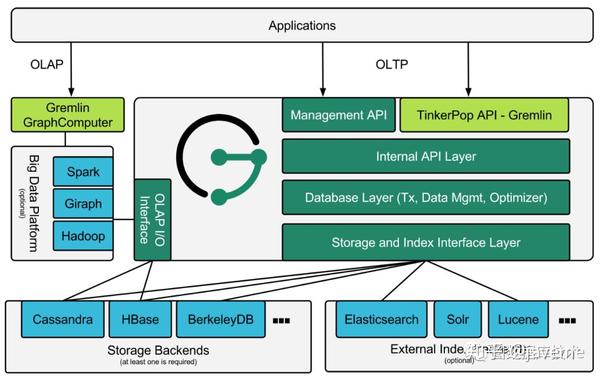

Janus整体架构分为3层,中间层是图引擎,最底层是存储层,最上层是应用程序层:
- 图引擎:图数据库核心,对外提供图方式的读写API。处理写请求,将数据索引起来、按照特定的格式写到存储层;处理读请求,按照特定格式从存储层高效读取数据,组装成图结果返回上层。
- 存储层:用于持久化图数据,包括两方面数据:1、图数据(包括顶点和边),存储在Storage Backend里面,可以选择配置一种后端存储,比如Cassandra或HBase;2、Mixed模糊索引数据(包括范围索引和全文索引等),存储在External Index Backend里面,也可以选则配置一种后端存储,比如ES或Solr;如果不开启Mixed模糊索引,则无需配置索引后端。
- 应用层:业务程序可以有两种方式来使用:1、内嵌到程序中,与业务程序共用同一个进程JVM;2、以服务的方式单独启动,业务程序通过HTTP API来访问。
数据模型/存储结构(整体)


图概念简介:图的核心是顶点和边,顶点代表现实世界中的实体,边代表现实世界中的关系,“我喜欢你”就可以抽象为两个顶点和一条边,同时顶点和边还可以有属性。
图是如何被存储的?在Titan/Janus中,使用的是邻接表存储结构(见上图,另一种流行的结构是Neo4j的邻接链表)。比对着上图来详细看:Janus把每个顶点的数据存为一行,当插入图数据时,会为每个顶点分配一个递增的Long类型ID(vertex id),查询的时候使用这个ID来进行索引查找。顶点的数据包括两方面内容:顶点属性(property)和邻接边(edge),每个顶点属性存为一列,每条邻接边也存为一列,列内部的详细结构见下一部分。
数据模型/存储结构(边及属性)


一个顶点的各顶点属性和边数据是按照顺序排列的,内部规则如下:
- 顶点属性:每个顶点属性包括:属性类型(key id)、属性ID(property id)、属性值(property value),各顶点属性按照属性类型的顺序依次存储。
- 边数据:边复杂一些,这里简化下讲最重点的核心思想,每条邻接边包括:边类型(label id)、边终点(adjacent vertex id)、边属性(other properties),各邻接边按照边类型+边终点组合的顺序依次存储。
Janus这种存储结构的优点是:
- 1、可以高效的查询一个点的邻接边:当需要查询一个顶点的所有邻接边时,先通过该顶点的ID快速定位到某一行,然后对这一行内的所有列依次读取,高效返回数据。
- 2、可以高效的查询一个超级点的小部分邻接边:如果只需要查询一个顶点的某种类型的邻接边时,可以根据边类型进行条件筛选,忽略掉其它类型的邻接边,加快读取速度。
针对上述第2个场景,邻接链表的存储结构是难于进行类似性能优化的。因此当一个顶点的邻接边超多时,即使用户只需要查询其部分邻接边,也还是需要从磁盘先读取所有邻接边,从而导致性能低下。
Janus大功能总结
- 支持Gremlin图语言,完全兼容TinkerPop框架;
- 支持4种后端存储:Cassandra、HBase、Bigtable、Berkeley;(此处Bigtable是Janus v0.1.0的增强)
- 支持严格的Schema元数据校验和丰富的数据类型;(此处是Janus v0.3.0的增强)
- 支持事务Transaction,是ThreadLocal隔离级别(个人理解为RC级),不保证ACID,严格的事务需要后端存储保证,Cassandra、HBase两个后端可支持最终一致性;
- 支持缓存Cache,有2种类型的缓存:
- 1、事务内缓存,生命周期和作用范围均在一个事务以内,包括`Vertex(adjacency) Cache`和`Index Cache`,可设置大小;
- 2、全局缓存,生命周期可超过事务,可设置大小和超时时间;
- 支持多节点部署服务,不过缓存同步是个问题,并不会被集群自动管理,需要靠缓存超时来减轻数据不一致;
- 支持图分区,除支持边切割之外,还支持supernode点内切割,点切割可以指定分区在一个VertexLabel上(how?);
- 支持TTL:支持顶点、边、属性的TTL;(此处HBase TTL部分是Janus v0.2.1的增强,详见#356)
- 支持Vertex-Centric索引,可以有效缓解超级点的查询性能问题;
- 支持二级索引(Composite Index),原生支持,加速如下查询:根据属性值精确匹配来查询顶点或边;
- 支持范围索引(Mixed Index),需要依赖第三方索引库如ES,支持查询方式包括:等于、大于、小于等;
- 支持全文索引(Mixed Index),需要依赖第三方索引库如ES,支持查询方式包括:textContains、textContainsPrefix、textContainsRegex、textContainsFuzzy、textPrefix、textRegex、textFuzzy。
- 支持空间位置索引,需要依赖第三方索引库,支持查询方式包括:geoIntersect、geoDisjoint、geoWithin、geoContains;(此处除geoWithin之外的方式是Janus v0.2.0的增强,详见#79)
- 支持单向边,只允许往out-going方向进行遍历;
- 可动态创建图实例。
Janus官方公布的技术限制:
- 最大支持2^60条边。
- 虽然允许定义Object类型,但是为了性能考虑,依然建议定义确切的类型。
- 根据ID获取一条边时,代价是O(log(k)),与邻接点的关联邻接边数量有关。(注:感觉官网说的有错误,理论上应该是与边的总数有关,代价是O(log(N))比较合理)
- 并发删除与更新操作,可能导致残留顶点的部分属性或边。
- 边不允许在跨事务中使用,包括创建或查询出来的边。
Janus实战问题总结:
- 只允许自动生成ID,不支持主键ID或用户自定义ID。当数据规模达到10亿并有大量覆盖写需求时,需要建立索引并在写之前进行大量随机读操作,导致整体性能严重降低。
- 大规模数据读取,返回大量查询结果时会爆内存,无法将全量数据读到客户端。
- 顶点的 [属性]列表 和 [邻接边]列表 两种数据存在一起(cells in a row),顶点和边读写性能相互影响严重。
- 顶点属性存为多个列(cell),其实并不利于OLTP查询性能,写入的KV对数量也增大若干倍。
- 边和属性存储了多余的ID,属性ID和边ID实际作用不大。
- 忽视后端存储的区别,所有的后端都当成是KV存储,使用大一统的序列化封装,以至于大部分默认的操作把整个顶点的邻接边和属性都读出来,浪费了IO资源、代价很大。
- 没有针对性的根据后端存储进行优化,比如数据类型、查询/计算下推等优化。
- 模糊索引依赖ES、Solr等外部系统,存在运维问题和双写问题。具体而言,部署运维麻烦,数据量大的时候问题很多,需要依赖ES专业人员调优;双写则引入额外问题,比如:数据一致性、图和索引两种后端性能不匹配、数据同步与稳定性等问题。(如:Vertex TTL does not remove indexed value from ES mixed index #987 )
- 元数据与索引的创建方式略复杂,配置项过多也导致运维难度增大。
- 缺少常用的图算法库,比如路径搜索、相似性等算法。
- 缺少导入数据、可视化界面、备份恢复等工具链。有一些第三方工具可供集成,但配置和使用起来都不是很友好。
面对这些问题,我们是如何解决的?请听下回分解。
原文链接:
Janus参考资料:
配置项文档:
https://docs.janusgraph.org/basics/configuration-reference/
技术限制:
https://docs.janusgraph.org/basics/technical-limitations/
https://docs.janusgraph.org/basics/common-questions/
数据类型支持:
https://docs.janusgraph.org/index-backend/search-predicates/#data-type-support
https://docs.janusgraph.org/basics/schema/
索引介绍:
https://docs.janusgraph.org/index-management/index-performance/
https://docs.janusgraph.org/index-backend/search-predicates/
数据模型:
https://docs.janusgraph.org/advanced-topics/data-model/
高级特性:
https://docs.janusgraph.org/advanced-topics/advschema/
第三方可视化界面集成:
Arcade Analytics, Cytoscape, Gephi plugin for Apache TinkerPop, Graphexp, Key Lines by Cambridge Intelligence, Linkurious and Tom Sawyer Perspectives.
Janus版本增强:
https://github.com/JanusGraph/janusgraph/blob/master/docs/changelog.md
https://github.com/JanusGraph/janusgraph/milestone/1?closed=1
文章被以下专栏收录

图数据库

数据库内核
