深入理解进程之创建调度切换
关注
“脚本之家
”,与百万开发者在一起

本文经Rand(id:Rand_cs)授权转载
如若转载请联系原公众号
本文接着上文 深入理解进程之数据结构篇 来讲述有关进程的一些操作,主要就是创建,调度切换,加载程序,休眠唤醒,等待退出等等,本文先来讲述进程的创建与调度切换三个方面,废话不多说,来看。
调度切换
关于第一部分想了半天,决定还是将进程的调度与切换放在开头,按道理说应该先讲述进程的创建,但是进程的创建与切换息息相关,只有先把进程的切换弄清楚了,才能明白进程的创建,所以还是先将进程的调度切换给说了吧。
开门见山,主要有两个事件会触发进程的调度与切换:
一个进程的时间片到了,该下 了
一个进程因为某些事件阻塞主动让出
一个进程的时间片到了,该下 了
一个进程因为某些事件阻塞主动让出
进程切换分为三个步骤:
进程切换到调度程序
调度程序挑一个进程
调度程序切换到进程
进程切换到调度程序
调度程序挑一个进程
调度程序切换到进程
前后两个步骤为切换操作,中间步骤为调度操作。 切换进程实际上进行了两次切换,第一次从 进程切换到调度程序,调度程序根据调度算法选择出一个进程 之后,再切换到进程 。
进程的切换就是上下文的保存与恢复,发生了两次切换操作,就会有两次内核态的上下文保存与恢复。而切换一定是在内核进里面进行的,并且进程切换完成之后一定会退出内核,所以还会涉及到用户级上下文的保存与恢复,因此进程切换如下图所示:
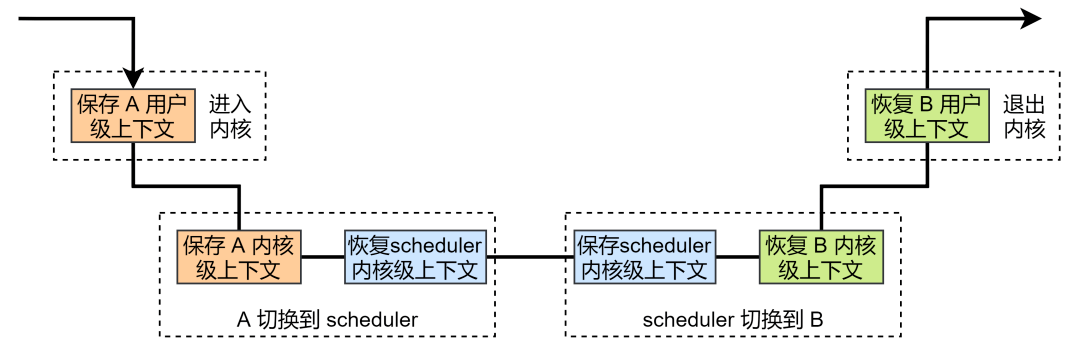
切换和调度都是两个内核函数,所以要弄清楚进程的调度与切换,主要就是弄清楚切换与调度两个函数,先来看切换函数
切换函数
函数原型:
voidswtch(struct context **old, struct context * new) ;
函数定义:
.globl swtch
swtch:
movl 4(%esp), %eax
movl 8(%esp), %edx
# Save old callee-saved registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-saved registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
切换函数很短也很对称,上下两段分别表示保存 的上下文和恢复 的上下文
进程A切换到调度程序
这个函数空口讲述不太好说,用实际例子来说明,比如现在是从进程 切换到调度程序 ,进程 的任务结构体指针为 ,当前 的指针为 ,则会这样调用切换函数:
swtch(&a->context, c->scheduler) ,调用前将参数返回地址压栈,所以内核栈中情况如下:
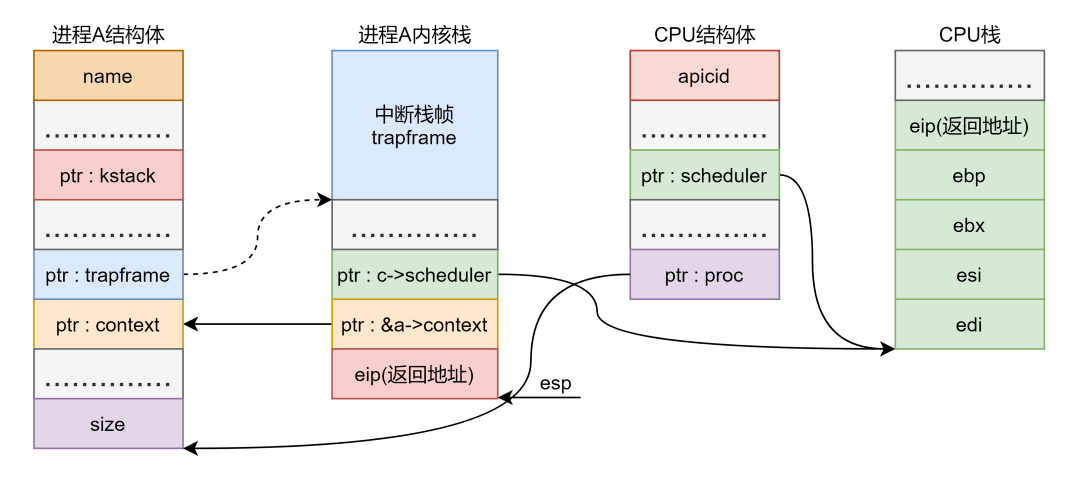
进程 内核栈里面的情况如第二个方框所示,我还把 的栈和结构体画出来了,各种指代关系应该是很明了的,就是有亿点点多,注意两点:
的第一个参数是个二级指针,在我们的例子当中就是 ,这个二级指针是进程 结构体中 这个属性字段的地址值。
图中的实线才是有着实际的指向关系,而虚线没有没有没有,我曾经在这儿出过错,为了提醒我自己说三遍。结构体里面的指针就是个变量,只有给它赋值的时候才会使它指向某个位置,不改变它的值的话,它就会一直指向某个位置,但这是无效的。我这里主要是想表示一下各种数据结构中变量的指向,其实不应该画出来的。但如果是因为系统调用进入内核的话, 那根线的确是实线,因为处理系统调用的过程中有个更改 的赋值语句。而 这个指针是一直指向内核栈的首地址(不是栈顶),这在后面 部分还有提到。
的第一个参数是个二级指针,在我们的例子当中就是 ,这个二级指针是进程 结构体中 这个属性字段的地址值。
图中的实线才是有着实际的指向关系,而虚线没有没有没有,我曾经在这儿出过错,为了提醒我自己说三遍。结构体里面的指针就是个变量,只有给它赋值的时候才会使它指向某个位置,不改变它的值的话,它就会一直指向某个位置,但这是无效的。我这里主要是想表示一下各种数据结构中变量的指向,其实不应该画出来的。但如果是因为系统调用进入内核的话, 那根线的确是实线,因为处理系统调用的过程中有个更改 的赋值语句。而 这个指针是一直指向内核栈的首地址(不是栈顶),这在后面 部分还有提到。
准备好参数之后就开始执行 函数了,首先是两个 mov 语句,很简单,取参数放到寄存器中。 放到 中, 放到 中。
接着压栈四个寄存器值,保存进程 的内核部分上下文,此时栈中布局没有太大变化:
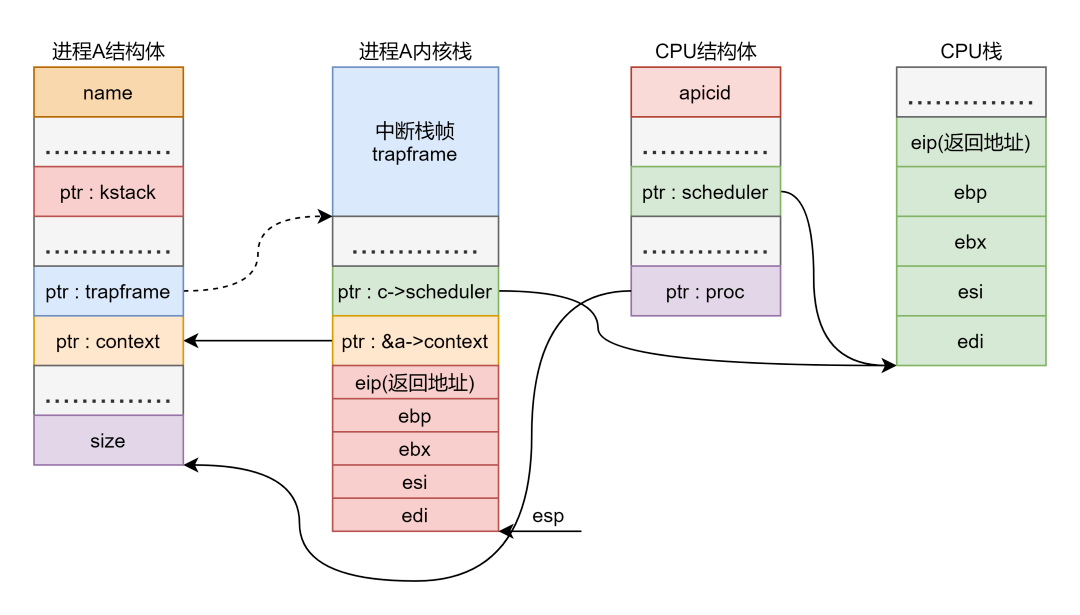
这一部分要注意 定义了 5 个寄存器,但实际只显示压栈了 4 个,还有个 (返回地址)是在调用 时隐式压栈的
接着又是两个 mov 语句:
movl %esp, (%eax)
movl %edx, %esp
这两个 mov 语句是核心,因为这是一个换栈的过程 :
将进程 A 的内核栈栈顶保存到任务结构体的 context 字段
将 的内核栈栈顶赋值给 esp 完成换栈
将进程 A 的内核栈栈顶保存到任务结构体的 context 字段
将 的内核栈栈顶赋值给 esp 完成换栈
又是注意两点:
进程 A 的栈顶地址保存到了任务结构体的 context 字段而不是 kstack 字段,虽然感觉从命名上来说 kstack 才是内核栈地址,但实际上 kstack 没多少用,具体用处见后面 TSS 部分。
的 context 字段值就是栈顶,原因在第一点,后面从调度程序切换到 B 的时候就会看到,将 的栈顶地址保存到 结构体的 context 字段,这样保持了一致性。
进程 A 的栈顶地址保存到了任务结构体的 context 字段而不是 kstack 字段,虽然感觉从命名上来说 kstack 才是内核栈地址,但实际上 kstack 没多少用,具体用处见后面 TSS 部分。
的 context 字段值就是栈顶,原因在第一点,后面从调度程序切换到 B 的时候就会看到,将 的栈顶地址保存到 结构体的 context 字段,这样保持了一致性。
现在栈中情况:
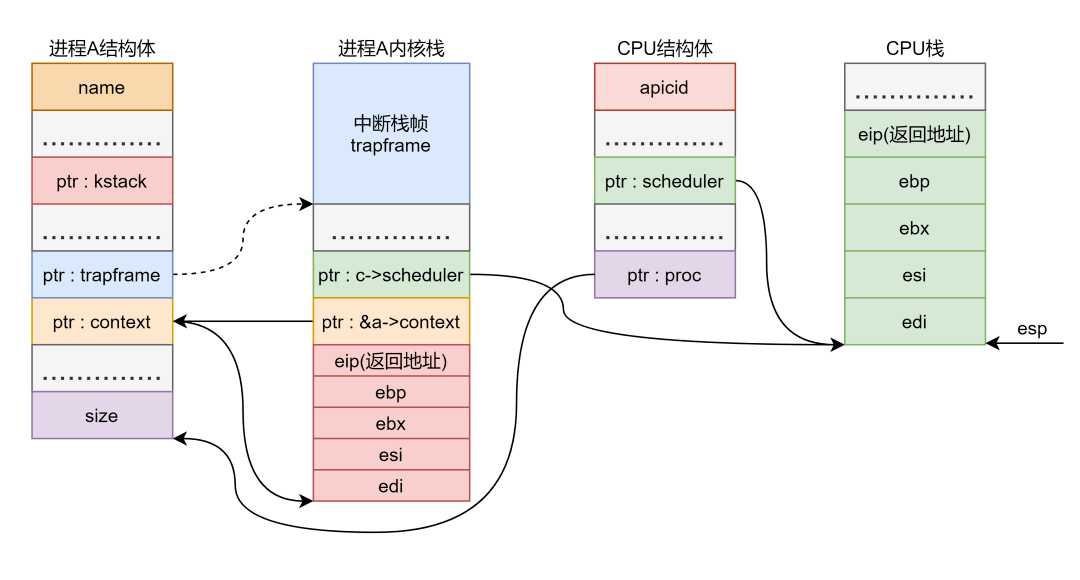
很清楚的看到现在 寄存器指向的是 栈而不是进程 的内核栈了,进程 的栈顶保存到了任务结构体的 字段后, 字段就指向了进程 的内核栈顶。
接着弹出四个寄存器,然后 ret 返回:
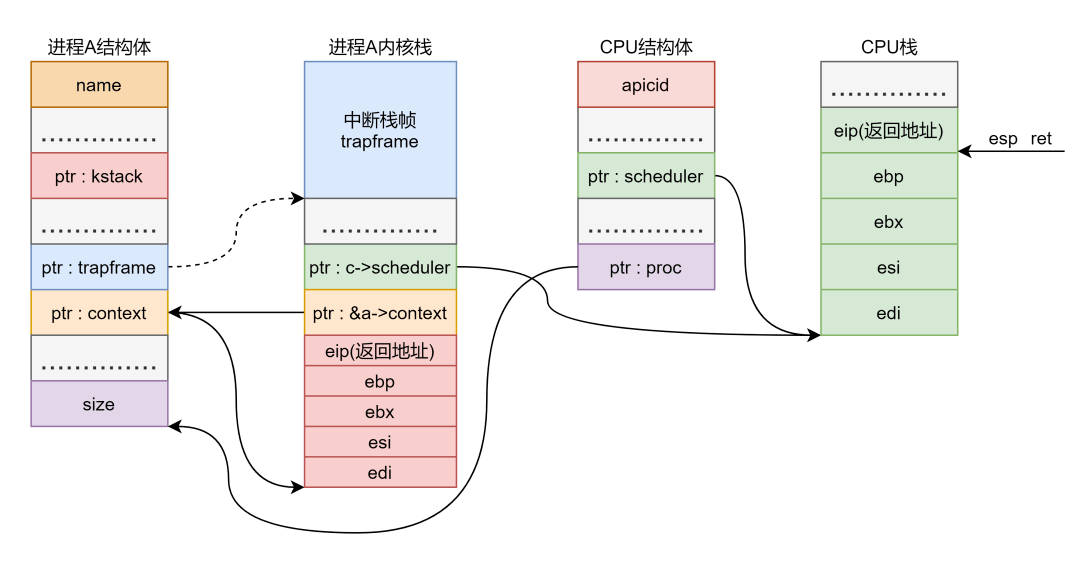
弹栈除了将值弹到相应地方,就只是改变 的值,不会做任何改变,所以各种指向关系没有任何变化。但要知道实际上右边那一块儿比如 的指针已经失效,等下次切换更新它的值才会有效 。
ret 的时候 应该指向返回地址,这个地址就是调度程序的返回地址,执行 ret 将其弹到 寄存器后就开始执行调度程序
调度程序
调度程序主要做两件事(感觉本文说的两件事有点多了啊):
根据调度算法挑一个进程出来,这里我们称之为进程
调用上述的 函数切换到进程
根据调度算法挑一个进程出来,这里我们称之为进程
调用上述的 函数切换到进程
我在多处理器下的调度中总结了常见的几种调度算法,诸位可以一观,其中就包括了 的调度。 的调度算法就是简单的轮询,平常各类书上网上讲的轮询是单个处理器的情况,多处理器下稍稍有些不同,来看示意图:
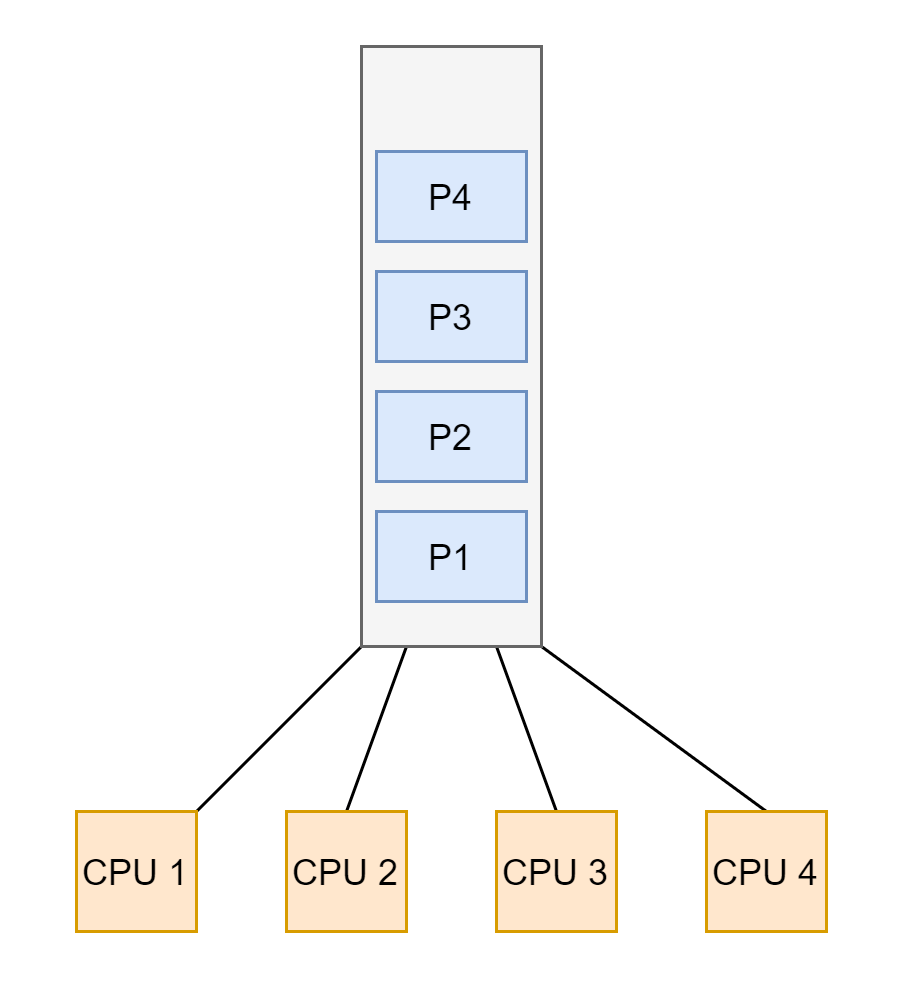
内核中只维护了一个全局的“就绪队列”, 为所有 共享。每个 都有自己的调度器,调度器从这个全局队列挑选合适的进程然后将 分配给它 。
单队列的形式实现起来比较简单,对所有的 来说很公平。这个队列是全局共享的,所以当一个 挑选进程时需要加锁,不然多个 就可能选取同一个进程 。但是锁机制不可避免带来额外的开销使得性能降低。
具体代码如下:
voidscheduler( void)
{
structproc* p;
struct$ CPU$ * c= my$ CPU$;
c->proc = 0;
for(;;){
sti; //允许中断
acquire(&ptable.lock); //取锁
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){ //循环找一个RUNNABLE进程
if(p->state != RUNNABLE)
continue;
c->proc = p; //此CPU准备运行p
switchuvm(p); //切换p进程页表
p->state = RUNNING; //设置状态为RUNNING
swtch(&(c->scheduler), p->context); //切换进程
/***************************************************/
switchkvm; //回来之后切换成内核页表
c->proc = 0; //上个进程下CPU,此时CPU上没进程运行
}
release(&ptable.lock); //释放锁
}
}
分割线之上的部分调度算法挑选一个进程 在切换到 的部分,分割线之后为从进程 切换到调度程序进行新一轮的调度。整个流程感觉上应该是很清晰也很简单,但实际上要细究的话这段代码很复杂
为什么要周期性地允许中断,为什么 之前需要取锁,这两个问题归根结底还是锁与死锁的问题,这在后面的文章详述。
另外对于调度程序中的 函数要有这个认识,它不会返回,执行到中途的时候就恢复了进程的上下文去执行进程了,而再次回到调度程序的时候此时 上没有进程再运行。这里说的有点超前了,下面还是继续调度程序切换到进程 的过程
调度程序切换到进程B
类似前面从进程 A 切换到调度程序 scheduler 调用 swtch(&a->context, c->scheduler) ,从调度程序切换到进程 B 就调用 swtch(&(c->scheduler), b->context) ,这个过程是几乎是一模一样的,不再赘述,最后看张图就可以了。 这里主要说明,切换到进程 之前需要做两件极其重要的事:更新 和 切换页表 ,这两件事都在 函数中进行,分别来看
更新
咱们在数据结构中重点说过 的作用就可简单的认为提供内核栈的地址 ,切换进程时必须要将其内核栈的地址写到 结构体里面,所以有了如下操作。
my$CPU$->gdt[SEG_TSS] = SEG16(STS_T32A, &my$CPU$->ts, sizeof(my$CPU$->ts) -1, 0);
my$CPU$->gdt[SEG_TSS].s = 0;
my$CPU$->ts.ss0 = SEG_KDATA << 3; //更改SS为新栈的
my$CPU$->ts.esp0 = (uint)p->kstack + KSTACKSIZE;
my$CPU$->ts.iomb = (ushort) 0xFFFF; //用户态禁止使用io指令
ltr(SEG_TSS << 3); //加载TSS段的选择子到TR寄存器
这是 的源码,大胆地评论一句,私以为这样写不太好, 根据前文的分析, 现在唯一的作用就是提供内核栈的地址,所以在切换进程的时候也应该只对 的 字段做更新,甚至 都不需要更新,因为平坦模式共用选择子嘛 。
对此我对 的代码做了如下修改,除开更新 的部分,我将其他部分集中在一起写进了计算机启动时的初始化代码里面:
staticvoidtssinit( void) {
struct$ CPU$ * c;
c = &$CPU$s[$CPU$id];
c->gdt[SEG_TSS] = SEG16(STS_T32A, &my$CPU$->ts, sizeof(my$CPU$->ts) -1, 0); //在GDT中注册TSS描述符
c->gdt[SEG_TSS].s = 0; //修改S位表示这是一个系统段
c->ts.ss0 = SEG_KDATA << 3; //选择子使用内核数据段选择子
c->ts.iomb = (ushort) 0xFFFF; //禁止用户态使用IO指令
ltr(SEG_TSS << 3); //加载选择子到TR
}
在初始化代码中加进这个 初始化函数:
/*******main.c********/
intmain( void) { //初始化BSP的tss
/****略*****/
tssinit;
/****略*****/
}
staticvoidmpenter( void) { //初始化AP的tss
/****略*****/
tssinit;
/****略*****/
}
因为 支持多处理器, 和 的启动代码稍有不同,两者都需要调用 来初始化,下面来看看这段初始化代码:
按照以前的进程切换方式,每个进程都要有一个单独的 ,但是效率太低,不使用这套。 这里是每个 一个,所有进程共享。 是内存的一段数据,需要在 中注册,所谓注册就是在 添加一个 描述符,将 的基址,界限,类型填进去。 是硬件支持的一种数据结构,硬件运行必须要有这个结构,有这样特点的内存数据段(广义的数据)就叫做系统段,系统段的描述符 位需要置 0。而像是常说的进程代码段数据段(狭义的数据)都不是系统段,它们的 位都是 1 。
内核栈段使用内核数据段的选择子, 位图的基址设为 ,这个位置超过了 界限,表示 位图不存在, 位图不存在表示只有 能够决定当前特权级能否使用 指令。 的 位一直是 0,则表示只有内核能够使用 指令。
最后将 的选择子加载到 ,这样 才能够知道 在哪,这就是 的初始化部分,这些都不需要再次改变,每次进程切换时只需要更新 的值,将其修改为:
my$CPU$->ts.esp0 = (uint)p->kstack + KSTACKSIZE;
为什么 是个固定值 ,也就是如下图所示:
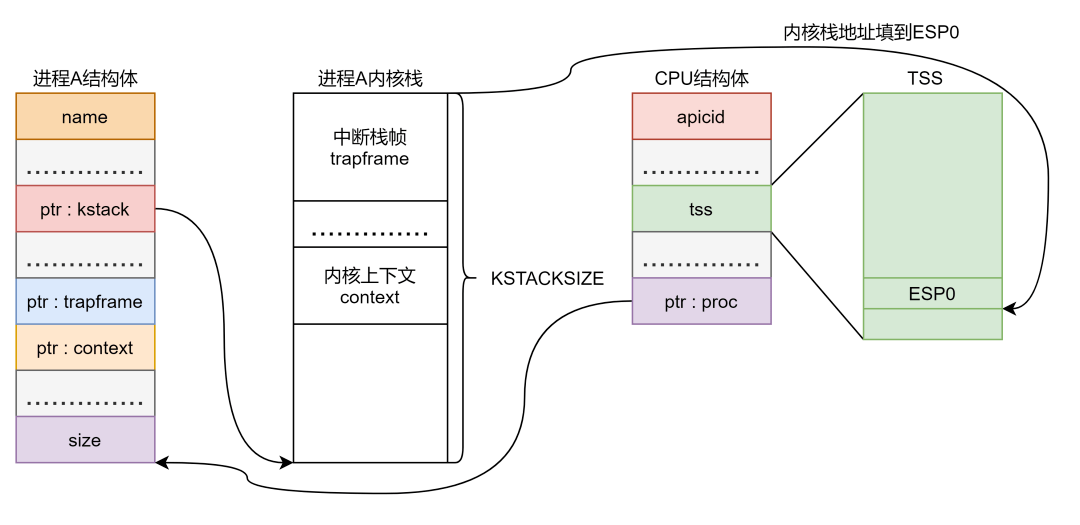
从这个图里面可以很清晰的看出 的值就是进程内核栈的栈底,这说明什么?说明退出退出内核时内核栈是空的,为什么会这样呢?这个问题在进程创建的时候解释,避免一会儿说这儿,一会儿讲那儿。
切换页表
上面为更新 ,实际上就只需要更新 中的 为新进程的内核栈地址,每个进程都工作在自己的虚拟地址空间里面,所以切换进程的时候还得把页表给切换了。
lcr3(V2P(p->pgdir));
切换页表就一条语句,将新进程 的页目录地址加载到 寄存器。 放进 的页目录地址一定是个物理地址,地址翻译就是要从 中获取页目录地址,如果这个地址是个虚拟地址,那还得翻译这个地址岂不“无限递归”出错了嘛,所以 中一定得放物理地址,因此使用 这个宏将虚拟地址转化为物理地址
从调度程序切换到进程 B 的图示如下:

到此进程的切换过程完毕,下面再来说说进程的创建。
创建普通进程
有了前面进程切换的铺垫,理解进程的创建就简单多了。在 或者 里除了第一个 进程需要内核来创建之外,其他的所有进程都是使用 来创建,第一个进程的创建放在本文最后一个部分,这一节先来看普通进程的创建方式,也就是 函数的实现
函数大家应该听得多也用得多了,我在使用分身术变身术创建新进程一文中也说过, 就好比分身术,以父进程为模板克隆出一个几乎一模一样的子进程出来。克隆的方式也分种类,有朴实无华(傻不拉几)版本的,也有十分巧妙(写时复制)的版本。 的 实现就很朴实无华,将父进程所有的东西几乎都复制了一份。
虽然很”朴实“,但也从中也还是能够学到 的基本思想,这里先将 函数会做的事情罗列出来,好有个大概把握
分配任务结构体,初始化任务结构体
分配内核栈,模拟上下文填充内核栈( 时此步骤无用)
复制父进程数据、创建页表
复制文件描述符表
修改进程结构体属性。
分配任务结构体,初始化任务结构体
分配内核栈,模拟上下文填充内核栈( 时此步骤无用)
复制父进程数据、创建页表
复制文件描述符表
修改进程结构体属性。
关于源码我就只放核心代码了,一些定义还有一些“不太重要”的操作比如上锁放锁就不摆出来占用空间了。一般函数里面锁的使用比较简单,困难重点的部分后面有专门的一节来讲述。这里先来看任务结构体的分配
staticstruct proc* allocproc( void) {
/*************略*************/
/*从头至尾依次寻找空间任务结构体*/
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++)
if(p->state == UNUSED)
gotofound;
/*************略*************/
}
从前置后遍历任务结构体数组,寻找空闲的任务结构体,也就事寻找状态为 的结构体,找到之后就跳转到
found:
p->state = EMBRYO; //设置状态为EMBRYO
p->pid = nextpid++; //设置进程号
找到一个空闲任务结构体之后就将其状态设置为 ,意为该结构体刚分配处于,正处于“萌芽”期。
是一个全局变量,初始值为 1,每创建一个进程该值就会递增。
任务结构体的分配很简单,就这么多, 函数的后续部分为分配和初始化内核栈部分
分配和初始化内核栈if((p->kstack = kalloc) == 0){ //分配内核栈
p->state = UNUSED; //如果分配失败,回收该任务结构体后返回
return0;
}
sp = p->kstack + KSTACKSIZE; //栈顶
// #define KSTACKSIZE 4096
使用 函数在空闲空间分配了一页作为内核栈,它位置不固定,完全却决于当时内存的使用情况。如果分配内核栈失败就将刚分配的任务结构体回收(状态设置为 )再返回。
使用 分配的一页空间时返回的是这页的首地址(低地址),刚分配的栈肯定是空的,所以栈顶为这页的首地址加上页大小
接下来就要初始化内核栈,在这刚分配内核栈里面做文章了,也就是与进程切换相关的部分来了。从前面我们知道进程的切换实质上就是上下文的保存与恢复,那这与进程的切换有什么关系?我们来捋一捋假如只分配栈空间但不做什么修饰会出现什么情况?
新进程是在内核创建的,我们且称之为进程 ,当 A 创建好后,想上 执行就需要被调度,然后与正在执行的进程 B 进行切换操作(这里我省略了切换到调度程序的过程)。切换操作就是保存 的上下文到 的内核栈,这没什么问题,还有就是恢复 的上下文,恢复上下文的操作就是弹栈,而弹栈那也得有东西弹是吧,而刚才似乎只分配了栈空间里面并没有什么内容?
由此,就捋出来了,我们需要对新进程的内核栈里面填充上下文,填充内核级上下文以便切换的时候需要,填充用户级上下文,以便从内核回到用户态的时候需要。其中用户级的上下文是复制的父进程的,这在后面会看到,而内核级上下文才是模拟填充的。
有了上述了解,回到 函数:
sp -= sizeof*p->tf;
p->tf = (struct trapframe*)sp;
这里就是先在栈中预留出中断栈帧的空间,然后将中断栈帧的地址记录在 里面。这里说明了分配的空栈里面首先存放的是中断栈帧,根据前面的进程切换我们知道在回到用户态的时候需要恢复用户级的上下文,就是将中断栈帧里面的东西给弹出去。弹出去之后内核栈就变为空栈了, 所以对于内核栈,不论中间情况多么复杂,但是栈底部分一定是用户级的上下文,退出内核时恢复用户级的上下文又会使得内核栈空。
sp -= 4;
*(uint*)sp = (uint)trapret;
这一步将中断返回程序的地址放进去
sp -= sizeof*p->context;
p->context = (struct context*)sp;
memset(p->context, 0, sizeof*p->context);
p->context->eip = (uint)forkret;
这一步模拟内核态上下文的内容, (返回地址) 填写为 函数地址
所以当该进程被调度的话,会先去执行 函数,执行完之后再返回执行中断返回函数,中断返回后就回到用户态执行用户程序了。这部分详见 多处理器下的中断机制
上述为分配任务结构体,分配内核栈,模拟上下文的过程,接着来看 函数:
复制数据创建页表if((np->pgdir = copyuvm(curproc->pgdir, curproc->sz)) == 0){
kfree(np->kstack);
np->kstack = 0;
np->state = UNUSED;
return-1;
}
函数会复制父进程用户空间的数据并创建新的页表。如果复制过程中出错,回收上面分配的一切资源再返回。
pde_t* copyuvm( pde_t*pgdir, uint sz) {
/***********略**********/
if((d = setupkvm) == 0) //构造页表的内核部分,内核部分都是一样的
return0;
for(i = 0; i < sz; i += PGSIZE){ //循环用户部分sz
if((pte = walkpgdir(pgdir, ( void*) i, 0)) == 0) //返回这个地址所在页的页表项地址,判断是否存在
panic( "copyuvm: pte should exist"); //为0表示不存在,panic
if(!(*pte & PTE_P)) //判断页表项的P位
panic( "copyuvm: page not present"); //如果是0表不存在,panic
pa = PTE_ADDR(*pte); //获取该页的物理地址
flags = PTE_FLAGS(*pte); //获取该页的属性
if((mem = kalloc) == 0) //分配一页
gotobad;
memmove(mem, ( char*)P2V(pa), PGSIZE); //复制该页数据
if(mappages(d, ( void*)i, PGSIZE, V2P(mem), flags) < 0) { //映射该物理页到新的虚拟地址
kfree(mem); //如果出错释放
gotobad;
}
}
returnd; //返回页目录虚拟地址
bad:
freevm(d); //释放页目录d指示的所有空间
return0;
}
进程在用户空间可以使用 ,但实际只用了 ,这个值记录在进程结构体中,前文数据结构篇@@@@@@@对这个值做了讲解,因为加载程序的时候以 0 为起始地址,所以 既表示当前进程在用户空间的大小又表示进程用户部分的末尾地址。
而 就是将这部分全部复制一份到子进程从 0 的虚拟地址空间,并建立映射关系创建一个新页表。 这说明了父子进程的虚拟地址空间是一样的,但映射到了不同的物理地址空间。整个流程应该还是挺清晰的:
根据父进程的页表得到用户部分虚拟页的物理地址
给子进程分配一物理页,复制数据
映射虚拟页和新分配的物理页
重复上述过程就是复制数据到新进程的用户空间以及创建新页表的过程,这里还有个隐含的注意点,上面一段代码乍一看挺简单的,但是想想这个问题, 复制数据的时候相当于是将一个用户空间的数据搬运到另一个用户空间去了,而每个进程的虚拟地址空间是独立的,我们常用的 、 等函数都是在同一个虚拟地址空间进行的,是不能跨越空间的 。
那如何解决呢?这里是用内核作为中转,所以 仔细看上述的 的使用,两个地址参数都是内核地址,两个虚拟空间的地址都转化成了内核地址,然后再做数据的搬运 。这里我就点到为止,如果有些许疑惑,我在后面的加载程序部分有详细的说明,因为加载程序部分有专门的函数,所以我放在那边详述。
复制文件描述符表,共享文件表
回到 函数,我稍微调整了一下源码的顺序,便于讲述。
for(i = 0; i < NOFILE; i++)
if(curproc->ofile[i])
np->ofile[i] = filedup(curproc->ofile[i]);
np->cwd = idup(curproc->cwd);
父子进程都有文件描述符表这个结构, 复制一份父进程的文件描述符表给子进程,这里虽然将文件描述符表复制了一份,但是文件描述符表里面存放的是指针,指向文件表,所以它两就是共享文件表 。
最后修改子进程的当前工作路径为父进程的路径,所有的这些文件管理都要调用专门的复制函数 ,因为文件系统对文件系统的引用数链接数有着严格的管理,详见了解文件系统调用吗?如何实现的?。
修改进程结构体np->sz = curproc->sz; //用户部分的大小
np->parent = curproc; //子进程的父进程是当前进程
*np->tf = *curproc->tf; //子进程的栈帧就是父进程的栈帧
// Clear %eax so that fork returns 0 in the child.
np->tf->eax = 0; //将中断栈帧的eax值修改为0
safestrcpy(np->name, curproc->name, sizeof(curproc->name)); //复制进程名字
pid = np->pid; //进程号,这是返回用的
acquire(&ptable.lock);
np->state = RUNNABLE; //子进程可以跑了!!!
release(&ptable.lock);
returnpid;
前面分配和初始化内核栈的时候只是预留了中断栈帧的空间,没有对其初始化,在这里直接将父进程的中断栈帧给复制了一份过来。中断栈帧是用户级上下文, 就是克隆出一个一模一样的进程,在前面已经复制了父进程用户空间的数据,这里再复制父进程的用户级上下文,如此 待到中断退出恢复上下文后,父子进程就是运行一样的程序(因为复制了用户空间的数据)并且从相同的地方开始执行(因为复制了用户级上下文)。
为什么没有复制内核级上下文?内核级上下文是进程切换的时候产生的,执行 函数的时候怎么可能执行切换函数呢是吧,所以这里与进程切换没什么关系,主要是创建的子进程要想被调度上 ,需要模拟填充上下文。这部分后面会有图解
另外中断栈帧里面的上下文也不是原封不动的复制过来,修改了 的值, 里面为返回值,将其修改为 0,这就是为什么对于子进程来说 返回值为 0 的原因。
代码剩余的部分就是对进程的名字,状态的处理,很简单,不再多说。
到此一个进程就创建好了,可以看出这简单版本的 实现起来还是很简单的,无非就是将父进程的所有东西全部复制一遍,除了上下文,进程号不大相同之外,其他的可以说是一模一样, 函数就到这里,最后来看一张图
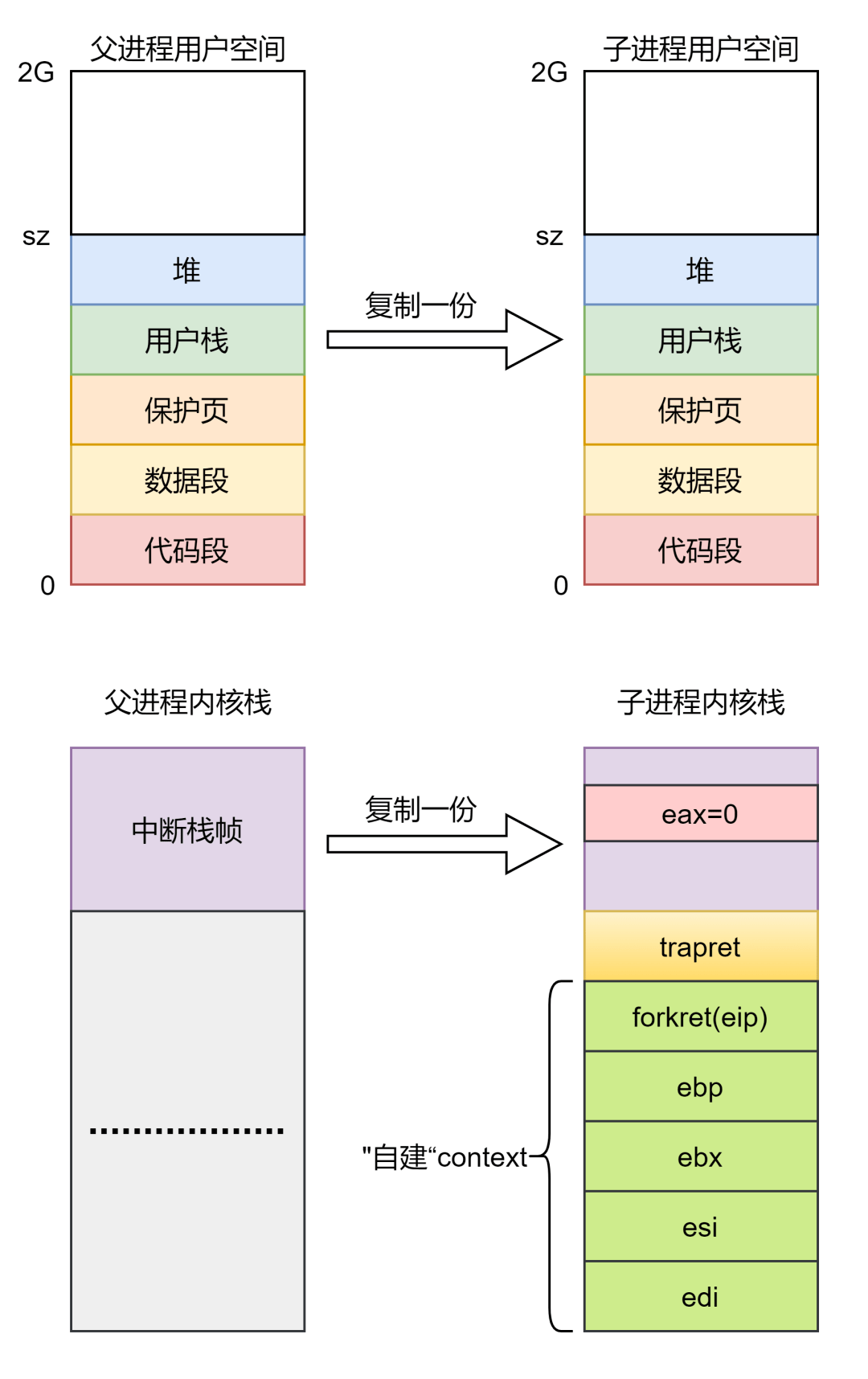
这张图显示了 主要复制了哪些数据。下面来看看子进程被创建后第一次被调度而后回到用户态的情景
子进程回到用户态
子进程的内核栈里面包括我们模拟填充的上下文,当它被调度上 执行的时候,具体的就是执行 后, 就会被加载到 ,然后执行 :
voidforkret( void) {
staticintfirst = 1;
release(&ptable.lock);
if(first) {
first = 0;
iinit(ROOTDEV);
initlog(ROOTDEV);
}
}
这个函数对于普通进程来说就是个空函数,这里普通函数是对于第一个进程来说的,第一个进程后面讲述,再者这个函数涉及到了释放 的操作,锁的问题也在后面集中讲述。所以这里就当作是个空函数就行了。
执行完之后去用户栈获取返回地址 ,随后执行 , 就是中断退出函数,将中断栈帧里面的上下文给弹出去,最后执行 退出中断回到用户态。这部分详见 多处理器下的中断机制
到此 函数讲述完毕, 主要是来创建普通进程,而第一个创建放在加载程序之后比较合适,本篇就先不讲述。
好了本文到这儿也结束了,本文主要讲述了进程的创建与切换,虽然是反着讲的,但影响应该不大。 普通进程的创建没什么技巧, 将父进程的“所有东西”赋值一份,而它想要被正确被调度执行切换函数的话,就需要将这个新进程模拟成旧进程为它填充内核级的上下文。而且最主要的是在内核里面放好要执行的函数地址 。
而进程的切换主要就是上下文的保存与恢复,其中最重要的步骤就是换栈,把握这两点就没什么问题了。
本文就先到这儿吧,有关进程方面后面的文章再继续,有什么问题还请批评指正,也欢迎大家来同我交流学习进步。
图解!24 张图彻底弄懂九大常见数据结构!
数据结构是如何装入 CPU 寄存器的?
程序员到底为什么要掌握数据结构与算法?
一文读懂 | 进程并发与同步
深入理解进程之数据结构篇
每日打卡赢积分兑换书籍入口 返回搜狐,查看更多
责任编辑: